Jstorm从源码编译及配置部署
虽然本文只是Jstorm的编译、配置、部署,但是仍需要对Storm的有基本的了解。
一、环境
- Jstorm使用的当前稳定版本2.1.1
- JDK使用1.7
- archlinux x64操作系统
- Jstorm依赖zookeeper,参考:Zookeeper从源码编译及配置部署
二、Jstorm编译
源码下载
从github上下载Jstorm源码
|
|
源码编译
Jstorm是java编写的,使用maven进行包管理,因此编译就比较简单了,直接通过下面得的maven命令就可以完成编译打包了(当前稳定版是2.1.1,git切换到稳定版本分支),编译好的包就是target下的’aloha-tgz.zip’包,解压出来就是Jstorm,其实打成zip包之前的目录就是target/aloha-tgz/jstorm-{version},这个目录就是Jstorm。
|
|
三、Jstorm安装
将上一步编译打包好的zip包拷贝到部署目录,然后解压出来,就完成安装了。(稳定版本的zip包也可以直接从官网下载)
四、Jstorm配置
根据官方文档第一步是要先配置JSTORM_HOME环境变量,但是根据后面的bin/jstorm启动脚本来看,这个环境变量并不需要。
- bin/jstorm是一个python脚本,作为Jstorm的启动脚本,2.1.1这个版本是通过bin/jstorm脚本自身的绝对路径反推出来JSTORM_HOME,因此这个环境变量在启动脚本中根本没有用到。
- 在Jstorm服务启动时,bin/jstorm脚本将Jstorm的home目录作为参数传递给了Jstorm服务,其中使用的参数名称是’jstorm.home’,并且在Jstorm服务读取storm.yaml这个配置文件时,用’jstorm.home’的值替换掉了storm.yaml中的所有包含%JSTORM_HOME%这个字符串的配置,因此即使没有配置JSTORM_HOME,在配置文件中依然可以使用%JSTORM_HOME%。
然后就是storm的主要配置文件conf/storm.yaml,个人测试环境storm.yaml配置如下:
|
|
配置说明:
storm.zookeeper.servers: 表示zookeeper的IP,不要包含端口,对于Zookeeper集群,需要将IP都配置上。
storm.zookeeper.port: 表示zookeeper的端口,默认为2181。
storm.zookeeper.root: 表示JStorm在zookeeper中的根目录,当多个JStorm集群共享一个zookeeper时,需要设置该选项,默认即为“/jstorm”。(建议生产环境配置独立的名称,以备后续的扩展需要)
storm.local.dir: 表示JStorm临时数据存放目录,Nimbus和Supervisor进程用于存储少量状态数据,如jars、confs等,需要保证JStorm程序对该目录有写权限。
jstorm.log.dir: 表示JStorm日志目录,默认为:$JSTORM_HOME/logs。
nimbus.host: Nimbus节点的地址,只支持IP,不支持域名,用于下载Topologies的jars、confs等文件。(也可不指定,启动nimbus节点后由于与Zookeeper交互会知道是哪个)
nimbus.host.start.supervisor: 表示是否允许在nimbus节点启动supervisor服务。(这个配置貌似只在bin/start.sh这个脚本中用了这个配置,如果不用这个脚本,这个配置就没任何作用了,还有待确认是不是只有这个脚本使用了)
supervisor.slots.ports: 表示Supervisor节点运行的worker能使用哪些端口,每个worker独占一端口用于接收消息,因此也定义了可运行的Woker数量。如果这个参数为空,则根据系统cpu数和内存数自动计算需要几个端口,并根据配置的基准端口为起始端口递增使用。
supervisor.slots.ports.base: 表示Supervisor节点运行的worker使用端口的基准端口,如果没有明确指明使用哪几个,则这个端口为基准递增使用。默认值为6800。
supervisor.slots.port.cpu.weight: 以cpu数计算worker数量的权重值,“cpu数/这个值”得到的值作为worker数量的参考值,这个值跟以memory权重计算得到的worker数值,取其中较小的一个值。
supervisor.slots.port.mem.weight: 以memory数计算worker数量的权重值,“memory数/这个值”得到的值作为worker数量的参考值,这个值跟以cpu权重计算得到的worker数值,取其中较小的一个值。
worker.memory.size: 每个worker内存大小,单位是byte。
java.library.path: 讲道理应该是Jstorm运行时的java lib path,未仔细研究,官方配置中有说明。
剩余配置当前未仔细研究,不做说明,官方配置中都有说明。
五、Jstorm运行
JStorm集群中包含两类节点:主控节点(Nimbus)和工作节点(Supervisor)。其分别对应的角色如下:
- Nimbus,它负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。
- 每个工作节点运行一个Supervisor,Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。
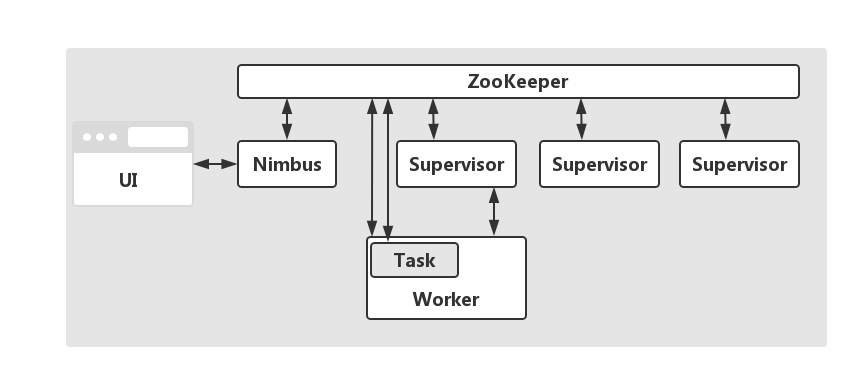
- ZooKeeper:系统的协调者
- Nimbus:调度器
- Supervisor:Worker的代理角色,负责Kill掉Worker和运行Worker
- Worker:一个JVM进程,Task的容器
- Task:一个线程,任务的执行者
启动前最重要的一个设置:
在/etc/hosts将当前hostname配置为本机IP,确保’hostname -i’命令可以获取到正确的本机IP,而不是127.0.0.1,否则会导致Jstorm获取不到本机IP或者host而启动失败,导致失败的原因是:这个信息在Jstorm向Zookeeper上注册相关信息时的必要信息。而且Jstorm在内部其他多处也需要使用这个信息。
nimbus启动命令如下,通过查看%JSTORM_HOME%/logs/nimbus.log检查有无错误(这个是默认日志路径,如果单独配置了日志路径,到配置的日志目录下查看)。
|
|
supervisor启动命令如下,查看%JSTORM_HOME%/logs/supervisor.log检查有无错误(这个是默认日志路径,如果单独配置了日志路径,到配置的日志目录下查看)。
|
|
nimbus服务关闭命令:
|
|
supervisor服务关闭命令:
|
|
Jstorm 2.1.1版本的一个bug:
- 在Jstorm启动失败的时候(比如当前主机ip由于是127.0.0.1的时候),这时Jstorm退出时并没有将Jstorm启动时在‘数据目录’下记录的pid文件删除,导致重新启动时,Jstorm检测到上次pid的文件,因此Jstorm会尝试杀掉这个pid的进程,但是其实这个Jstorm进程已经不存在,根据linux进程号的分配策略,这个进程号有可能又被分给了其他进程,那么这时这个进程就会因为这个原因被kill。这个pid的删除并没有在shutdown hook中处理?
Jstorm 2.1.1中易用性问题:
- Jstorm需要本机hosts中要配置本机IP,而用于注册到zk,虽然在生产环境一般这种方式没问题,但是用户单机测试环境等IP不固定而是DHCP分配的场景,hosts中就不会设置或者设置是localhost,就会导致Jstorm启动失败,这个最好是可以配置了,默认使用从hosts中读取的方式。
- 随后发现Jstorm中多出使用这种方式获取本机IP,DHCP测试环境下确实比较麻烦。
六、参考资料
Jstorm QuickStart Compile
Jstorm QuickStart Deploy
Jstorm Basic in 5 minutes
Jstorm Configration
(完结)